Abstract
Fine-tuning vision-language-action (VLA) policies for long-horizon manipulation still largely depends on behavior cloning, which requires costly high-quality demonstrations and limits policies to the demonstration distribution. Reward models can reduce this dependence by reweighting demonstrations and providing dense supervision for on-robot reinforcement learning (RL). However, an effective reward model must be dense, accurate, and general. Existing meth- ods do not satisfy all three: task-specific stage-aware models are dense and accu- rate but require per-task annotations, while general vision-language-model (VLM) based reward models are broadly applicable but too coarse and noisy for fine- grained long-horizon progress. To close this gap, we introduce SARM2, a multi- task stage-aware reward model that pairs a general action-primitive based stage estimator with a multi-gate Mixture-of-Experts (MMoE) value head, producing dense per-step rewards across multiple manipulation tasks. Built on SARM2’s ac- curate reward, we further design SPIRAL (Self-Policy Improvement via Reward- Aligned Learning), an on-policy reward-guided framework that refines a VLA policy from cheap autonomous rollouts using SARM2’s dense rewards. On a 10-task benchmark, SARM2 reduces value-estimation MSE by 80% over the strongest baselines; plugged into SPIRAL, it boosts task success from around 50% to nearly perfect on both Folding Shorts (58% → 100%) and Cleaning White- board (50% → 90%), evidencing that high-quality dense rewards are a critical ingredient for a stable robot data flywheel.
Overview of SARM2
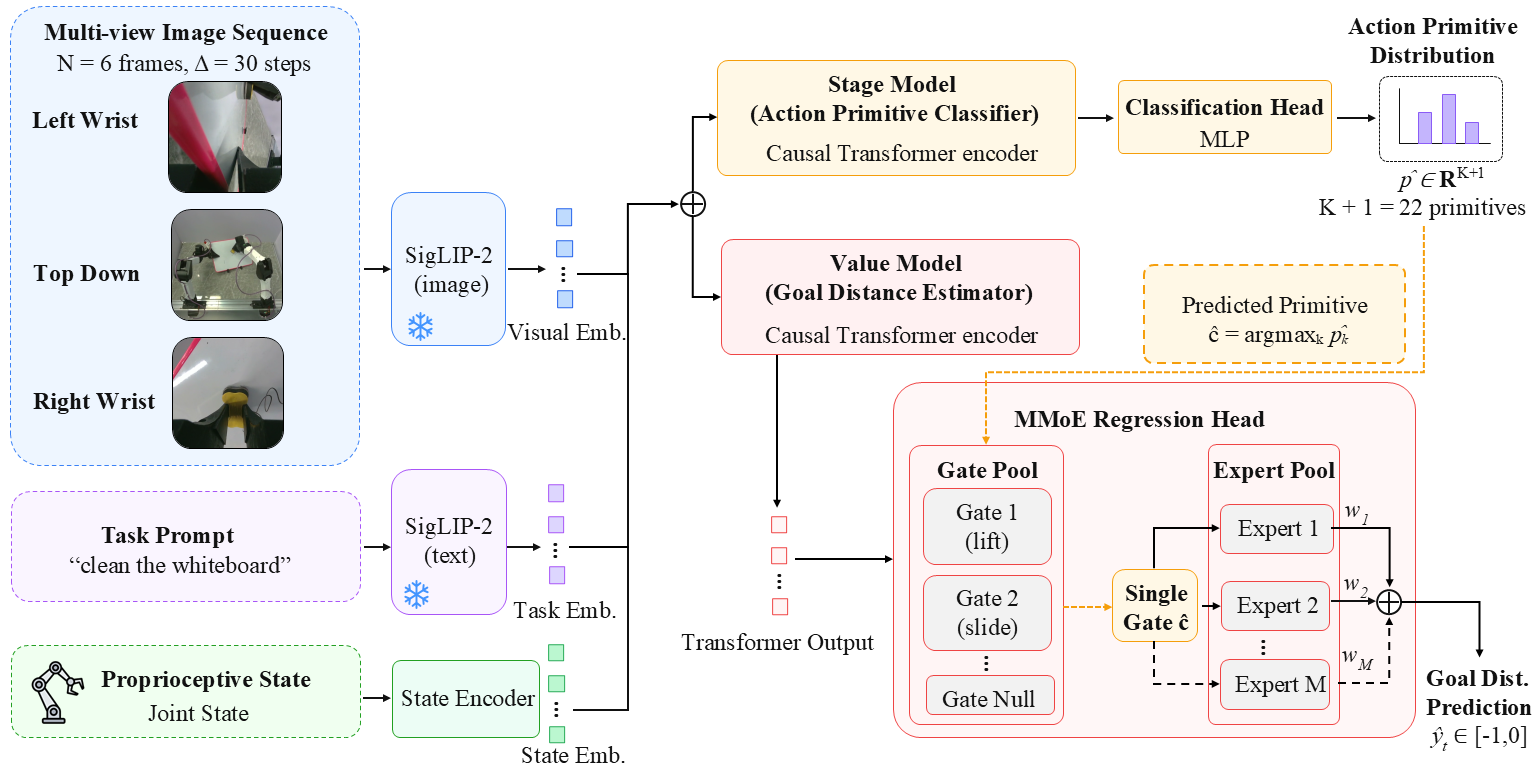
Three camera views plus proprioceptive state are encoded by a shared frozen SigLIP-2 backbone, whose cached frame embeddings feed two separately trained causal Transformers: (i) a task-agnostic stage estimator that classifies the current segment over K+1=22 candidates (K=21 action primitives and a null class used as a fallback when the model is uncertain), and (ii) a multi-gate MoE value decoder whose gate is selected by the predicted primitive group and routes the fused token through top-k shared experts to produce a dense progress estimate.
Results of SARM2 Value Estimation
Stage Estimation
Example videos show the stage estimator's predictions over action primitives and the downstream MoE expert selection. The results show a strong correlation between the predicted primitive and the selected experts.
Demo Data Estimation
Video samples of SARM2's value-estimation results across demonstration data from multiple tasks. Sarm2 provides dense and accurate value estimates for tasks ranging from around 30 seconds to over 2 minutes, all within a single model.
Policy Rollout Estimation
Examples of SARM2's prediction on policy rollouts on two qualitatively different tasks, Folding Shorts and Cleaning Whiteboard. SARM2 captures segment-level detail of the rollout: its predicted progress rises when the robot is making real progress, plateaus or dips when the robot is adjusting or struggling, and drops sharply at catastrophic failures, in agreement with the visualized key frames.
Folding Shorts
Cleaning Whiteboard
SPIRAL Workflow
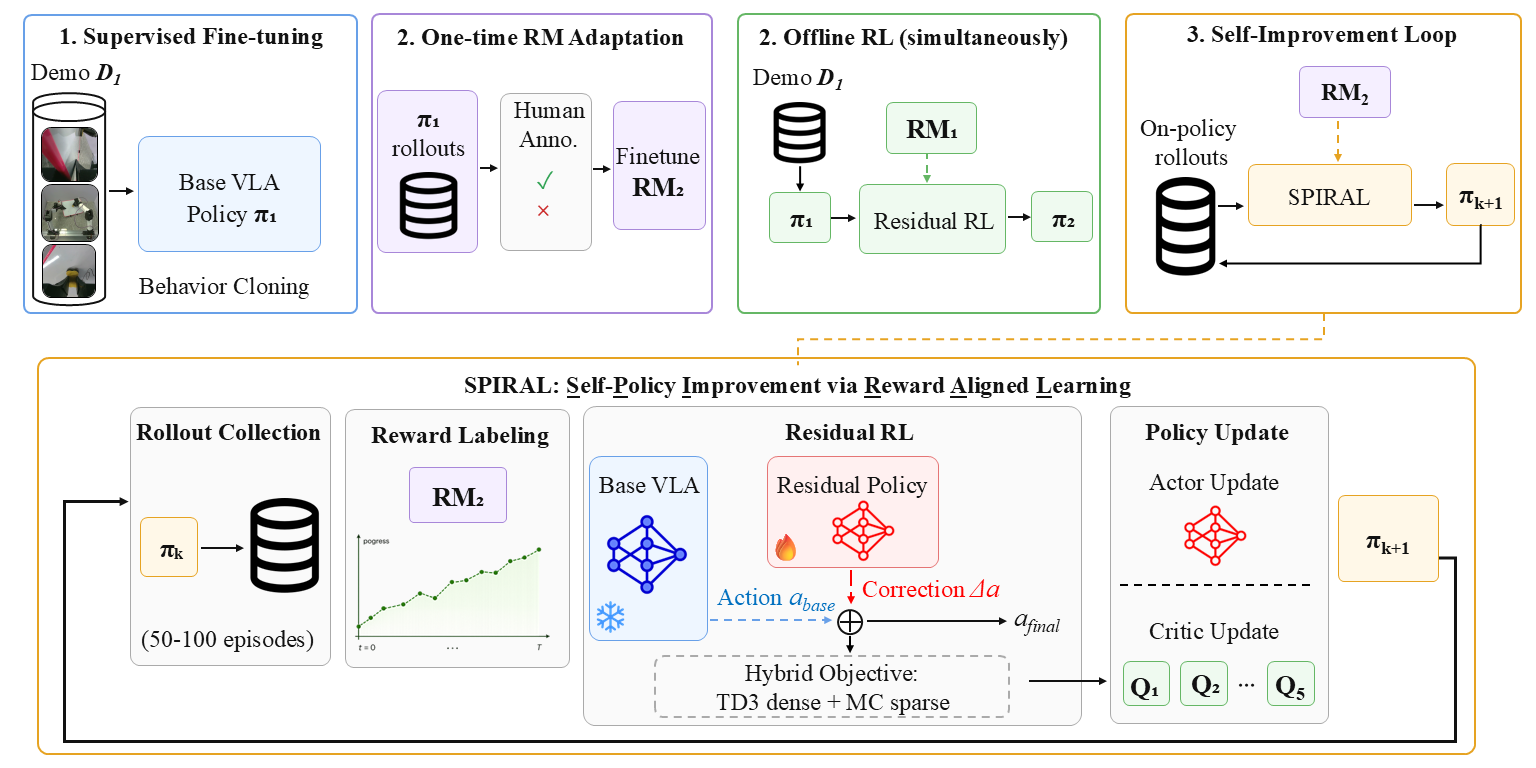
SPIRAL: SARM2-powered self-improvement framework. (1) BC fine-tunes πVLA on demos to obtain π1. (2) In parallel, (2a) a one-time human annotation of ~100 rollouts from π1 adapts RM1 → RM2 to cover the rollout distribution, while (2b) an offline SPIRAL update with the pretrained RM1 trains π2. (3) An autonomous loop then alternates rollout collection, RM2 relabeling, and SPIRAL updates with no further supervision
Policy Improvement with SPIRAL: Cleaning Whiteboard
Base BC Policy: Troublesome Rollouts
Policy Improvement with SPIRAL: Folding Shorts
Fold flat shorts
Fold Crumbled shorts
Unstopped Continual Rollout of SPIRAL improved Policies
Citations
If you find our work useful in your research, please consider citing: